Uncertain Health in
an Insecure World – 85
“Auspicious Beginnings“
In Ancient Rome, priests called augurs studied the flight and feeding patterns of birds to
prophesize the future. The word auspicious is derived from Latin, auspex, meaning “bird seeker.” The plural,
auspices, is often used to refer to “kindly
patronage and guidance.”


Precision medicine (PM) enjoyed an auspicious beginning.

In an April 24, 2015 TEDxSantaClara
talk, “Collaboration is the New
Competition,” David Haussler (University of California Santa Cruz Genomics
Institute director, above) describes how he guided Jim Kent (below), then a UCSCgrad
student, to write “killer” computer
code to sequence of the first human genome. In June 2000, Kent used a cluster
of one hundred work stations, each no more powerful than a modern cell phone,
to crack The Human Genome.


Their research was prescient – an example of radical collaboration.
Celera, founded
by Craig Venter, quickly scaled up commercial genome sequencing. Celera is now
a subsidiary of business giant, Quest
Diagnostics.
--------//--------
--------//--------
Next generation sequencing (NGS) transformed genomic
analyses.
Successful genome alignment and variant calling takes
intense computing efforts. Single nucleotide polymorphism (SNP) and insertion
and deletion (indel) mutation variant calling methods identify genome positions
with polymorphisms relative to a reference file. Variant calling yields
insights into nucleoside-level organismal differences between human and
microbial genomes. But variant calling is a multistep bioinformatics process
with a number of potential sources of error.


Converting millions of gene sequencing reads per sample
into meaningful data is hardly trivial.
A conscious human brain can fire 38 thousand
trillion synaptic messages per second!


The world’s most powerful supercomputer, IBM’s BlueGene, can manage about 0.002%
of that. But human beings have come to rely on supercomputers to make sense of
the world. In November 2015, Intel placed
its fastest 8-teraflop (8x1012 floating-point operations per second)
Knight’s Landing silicon chip into
desktop PC’s. Soon, handheld devices will put supercomputer performance into
the palms of teenagers.


In 2011, it took supercomputers approximately 10 days to
sequence a human genome. Since then, bioinformatics experts have been tackling
how to shift from local site computing power to Cloud data sharing. In 2013,
many institutional and national data repositories like the U.S. Veterans
Administration Million Veteran Program (below, left) contained such numerous genomes that would take one institution months to
sequence them.




The cost per genome being sequenced (above, right) began to dramatically
drop in 2008, paradoxically increasing the number of institutional genome data silos. Contemporaneously,
the clinical care of children with genetic diseases included more genomic data
embedded in electronic health records (EHR). Exomes are now sequenced
clinically to determine the metabolic fate of certain drugs, such as expensive Elelyso™ enzyme replacement therapy for
children with Gaucher’s Disease.

--------//--------
Bioinformatics is facing down the data sharing bottleneck.
In the research funnel (below), one’s proximity to a bottleneck determines how one approaches the problem.
In the research funnel (below), one’s proximity to a bottleneck determines how one approaches the problem.

In 2015, Stanford bioinformatics researchers began "nitty gritty" work with Google to query the NIH database of Genotypes and Phenotypes
(dbGaP) in the Cloud with BigQuery™,
dramatically reducing the time required to do a single data query for 30
million annotated variants to mere seconds (below).


With this advance, by applying Dremel technology (Apache Drill™, below), the era of open source genomic data mining began.
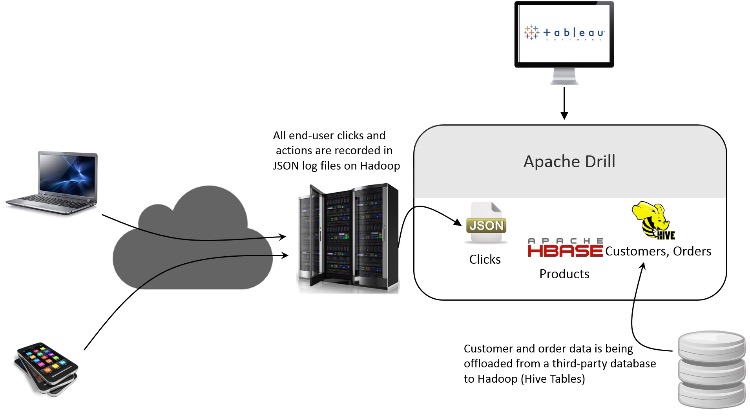
The recent convergence of open source Cloud computing and
gene sequencing scalability set the stage for the February 2016 Obama
Administration’s Precision Medicine
Initiative.

--------//--------

--------//--------
The last bottleneck is personal health information
(PHI) privacy.
The press is full of shocking privacy breech stories
involving healthcare insurance databases and EHR’s. Data sharing security concerns
related to PHI privacy have resulted in increased regulatory hurdles, reducing
data access and preventing research collaborations that could lead to real PM
progress.
In the end, the type of privacy required in the PM data
sharing milieu boils down to math. At the 2006 Proceedings of the Association of Computing
Machinery on Privacy, Stanford’s Philippe Golle showed that with an
individual’s birth date and 5-digit zip code, there is a 63.3% probability that
a U.S. person’s identity can be determined without any requirement for gender being
known.
According to Stanford’s Somalee Datta (below... and yes… it auto-corrects
to 'Data'), points-of-view on data privacy differ for patients (“My Health”), companies (“My Business”) and researchers (“My Research”).


Patients want
better healthcare for their children, themselves, their extended families and
community, and may be willing to accept the unknown risk and longer term
implications of genomic data loss.
Businesses seek
the value proposition associated with better healthcare for patients, but risk large scale
hacking, malicious ransomware, bad press and loss of consumer trust.
Researchers’
end game is effective data use for new discoveries that improve health, and they
are willing to tolerate complex data use agreements and/or negotiated service
agreements for data access.
In order for bioinformatics to relieve this last bottleneck
– timely data sharing with secure privacy protection – patients need
transparency regarding the use of their data (informed consent), businesses require secure platforms that allow
granular monitoring of data activity (like
financial systems currently utilize), and researchers want workflow
oriented bioinformatics suites that allow for flexible research plans (open access).
--------//--------

PM sits squarely at the interface between genomics big data and immense computing power.
How thinking humans grapple with this complex interface will define the usefulness of genomics data to the future practice of PM.
How thinking humans grapple with this complex interface will define the usefulness of genomics data to the future practice of PM.
If PM’s future is to augur well, bioinformaticians must get more patients’ big data into the hands
of more genomics researchers who work
on more powerful open-source analytic
platforms.
The precogs in the Square clearly see how the “kindly patronage and guidance” of
patients, businesses and researchers produced PM's auspicious beginning.
But we worry that PM could crash to Earth if regulators fail to properly read the chicken entrails.
But we worry that PM could crash to Earth if regulators fail to properly read the chicken entrails.








